publications
2025
-
 What Comes After Harm? Mapping Reparative Actions in AI through Justice FrameworksSijia Xiao, Haodi Zou, Alice Qian Zhang, Deepak Kumar, Hong Shen, Jason Hong, and Motahhare EslamiAAAI / ACM Conference on Artificial Intelligence, Ethics, and Society (AIES), 2025
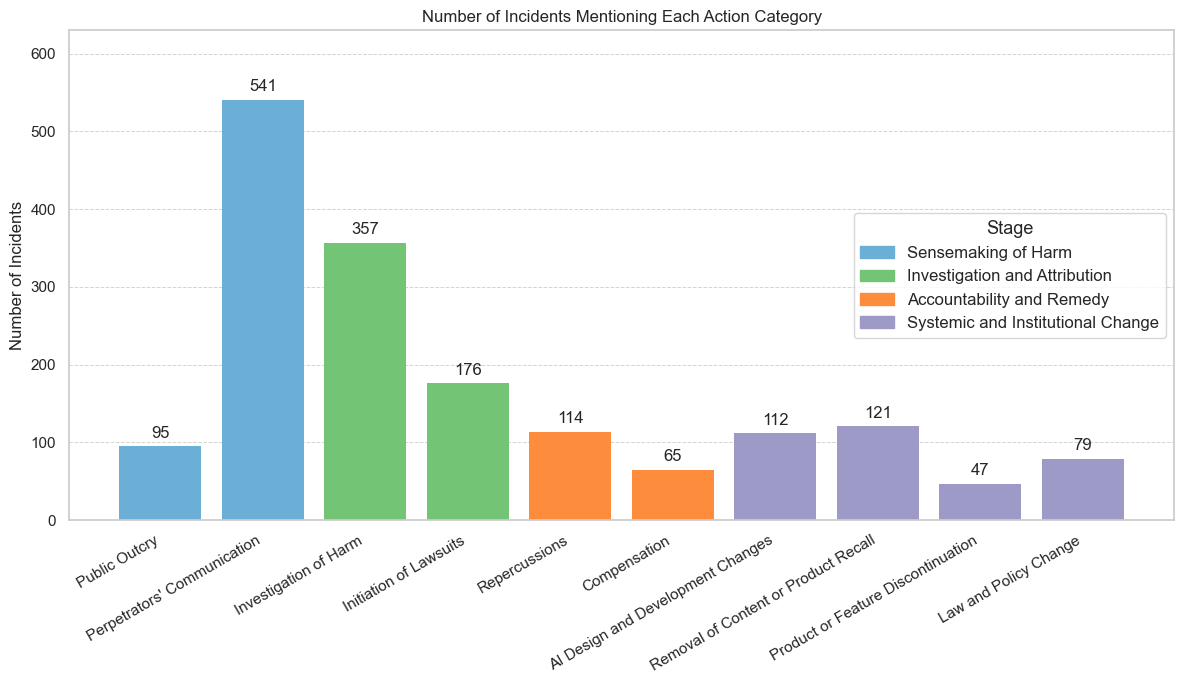
What Comes After Harm? Mapping Reparative Actions in AI through Justice FrameworksSijia Xiao, Haodi Zou, Alice Qian Zhang, Deepak Kumar, Hong Shen, Jason Hong, and Motahhare EslamiAAAI / ACM Conference on Artificial Intelligence, Ethics, and Society (AIES), 2025As Artificial Intelligence (AI) systems are integrated into more aspects of society, they offer new capabilities but also cause a range of harms that are drawing increasing scrutiny. A large body of work in the Responsible AI community has focused on identifying and auditing these harms. However, much less is understood about what happens after harm occurs: what constitutes reparation, who initiates it, and how effective these reparations are. In this paper, we develop a taxonomy of AI harm reparation based on a thematic analysis of real-world incidents. The taxonomy organizes reparative actions into four overarching goals: acknowledging harm, attributing responsibility, providing remedies, and enabling systemic change. We apply this framework to a dataset of 1,060 AI-related incidents, analyzing the prevalence of each action and the distribution of stakeholder involvement. Our findings show that reparation efforts are concentrated in early, symbolic stages, with limited actions toward accountability or structural reform. Drawing on theories of justice, we argue that existing responses fall short of delivering meaningful redress. This work contributes a foundation for advancing more accountable and reparative approaches to Responsible AI.
-
 SnuggleSense: Empowering Online Harm Survivors Through a Structured Sensemaking ProcessSijia Xiao, Haodi Zou, Amy Mathews, Jingshu Rui, Coye Cheshire, and Niloufar SalehiACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW), 2025
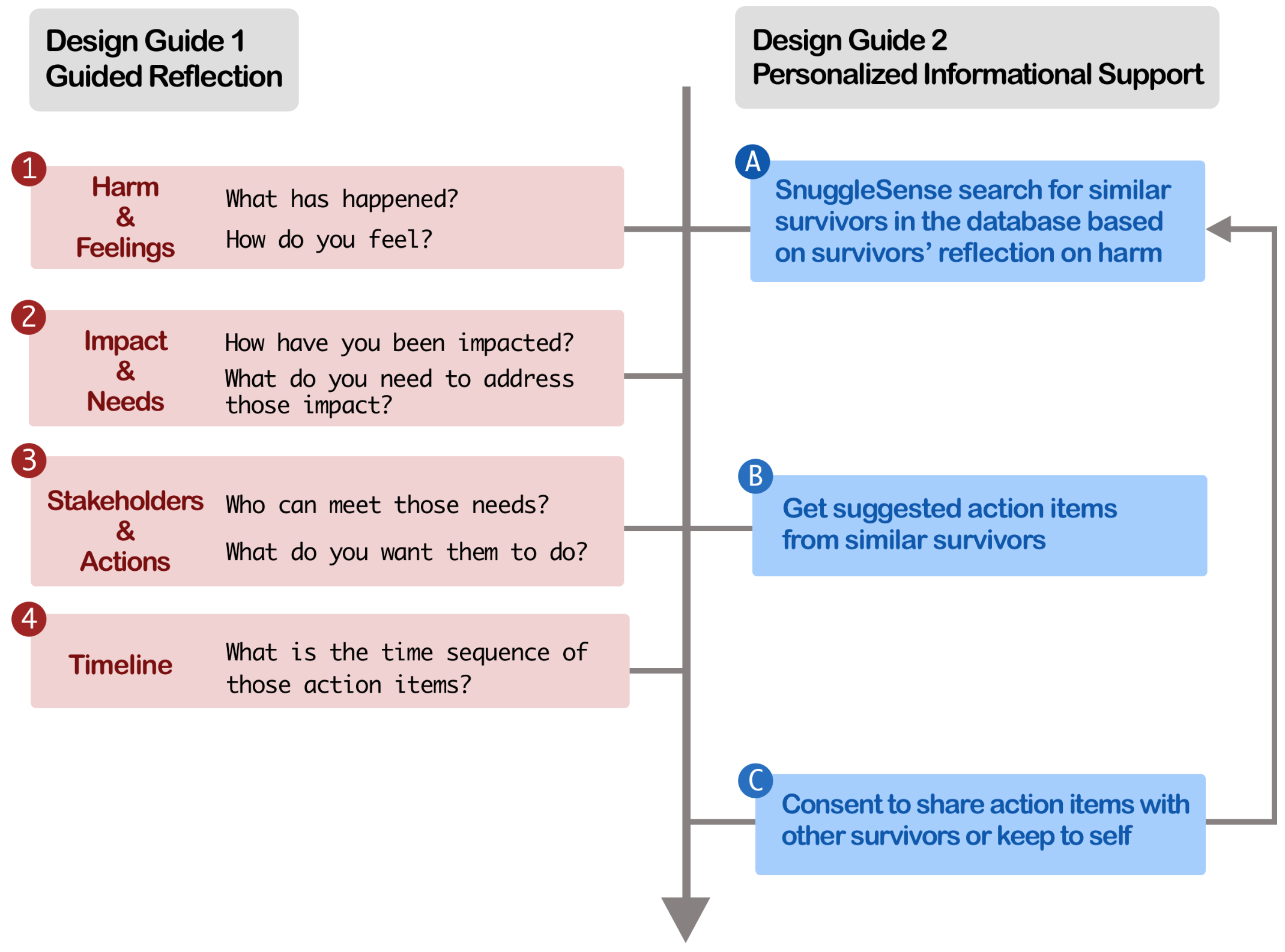
SnuggleSense: Empowering Online Harm Survivors Through a Structured Sensemaking ProcessSijia Xiao, Haodi Zou, Amy Mathews, Jingshu Rui, Coye Cheshire, and Niloufar SalehiACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW), 2025Online interpersonal harm, such as cyberbullying and sexual harassment, remains a pervasive issue on social media platforms. Traditional approaches, primarily content moderation, often overlook survivors’ needs and agency. We introduce SnuggleSense, a system that empowers survivors through structured sensemaking. Inspired by restorative justice practices, SnuggleSense guides survivors through reflective questions, offers personalized recommendations from similar survivors, and visualizes plans using interactive sticky notes. A controlled experiment demonstrates that SnuggleSense significantly enhances sensemaking compared to an unstructured process of making sense of the harm. We argue that SnuggleSense fosters community awareness, cultivates a supportive survivor network, and promotes a restorative justice-oriented approach toward restoration and healing. We also discuss design insights, such as tailoring informational support and providing guidance while preserving survivors’ agency.


2024
-
 SAGE: System for Accessible Guided Exploration of Health InformationSabriya M. Alam, Haodi Zou, Reya Vir, and Niloufar SalehiAAAI Workshop on Public Sector LLMs, 2024
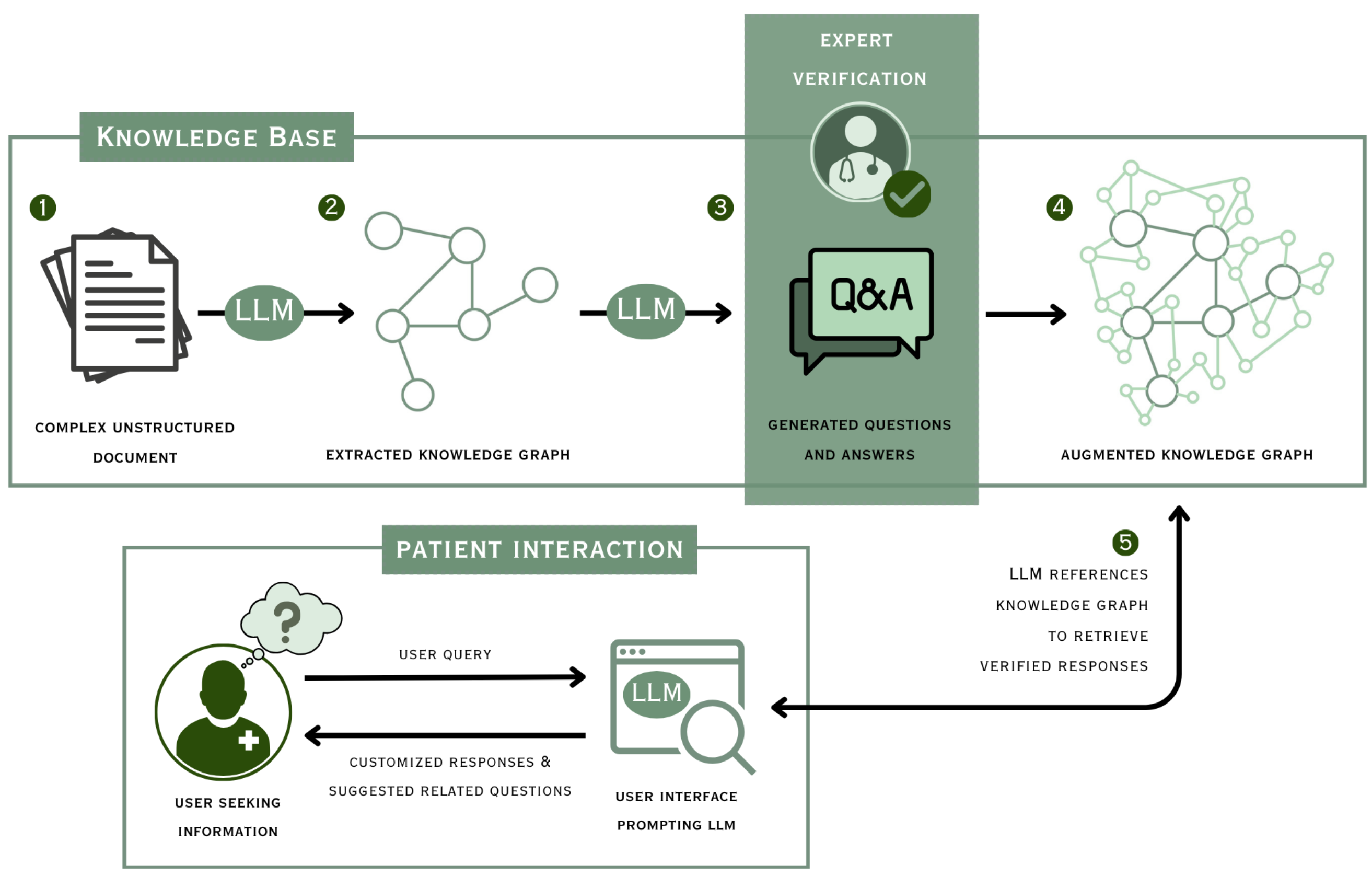
SAGE: System for Accessible Guided Exploration of Health InformationSabriya M. Alam, Haodi Zou, Reya Vir, and Niloufar SalehiAAAI Workshop on Public Sector LLMs, 2024The Center for Disease Control estimates that six in ten adults in the United States currently live with a chronic disease such as cancer, heart disease, or diabetes. Yet most patients lack sufficient access to comprehensible information and guidance for effective self-management of chronic conditions and remain unaware of gaps in their knowledge. To address this challenge, we introduce SAGE, a System for Accessible Guided Exploration of healthcare information. SAGE is an information system that leverages Large Language Models (LLMs) to help patients identify and fill gaps in their understanding through automated organization of healthcare information, generation of guiding questions, and retrieval of reliable and accurate answers to patient queries. While LLMs may be a powerful intervention for these tasks, they pose risks and lack reliability in such high-stakes settings. One approach to address these limitations is to augment LLMs with Knowledge Graphs (KGs) containing well-structured and pre-verified health information. Thus, SAGE demonstrates how LLMs and KGs can complement each other to aid in the construction and retrieval of structured knowledge. By integrating the flexibility and natural language capabilities of LLMs with the reliability of KGs, SAGE seeks to create a collaborative system that promotes knowledge discovery for informed decision-making and effective self-management of chronic conditions.
-
 ALOHa: A New Measure for Hallucination in Captioning ModelsSuzanne Petryk*, David Chan*, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E. Gonzalez, and Trevor DarrellConference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024
ALOHa: A New Measure for Hallucination in Captioning ModelsSuzanne Petryk*, David Chan*, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E. Gonzalez, and Trevor DarrellConference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024Despite recent advances in multimodal pre-training for visual description, state-of-the-art models still produce captions containing errors, such as hallucinating objects not present in a scene. The existing prominent metric for object hallucination, CHAIR, is limited to a fixed set of MS COCO objects and synonyms. In this work, we propose a modernized open-vocabulary metric, ALOHa, which leverages large language models (LLMs) to measure object hallucinations. Specifically, we use an LLM to extract groundable objects from a candidate caption, measure their semantic similarity to reference objects from captions and object detections, and use Hungarian matching to produce a final hallucination score. We show that ALOHa correctly identifies 13.6% more hallucinated objects than CHAIR on HAT, a new gold-standard subset of MS COCO Captions annotated for hallucinations, and 30.8% more on nocaps, where objects extend beyond MS COCO categories.

